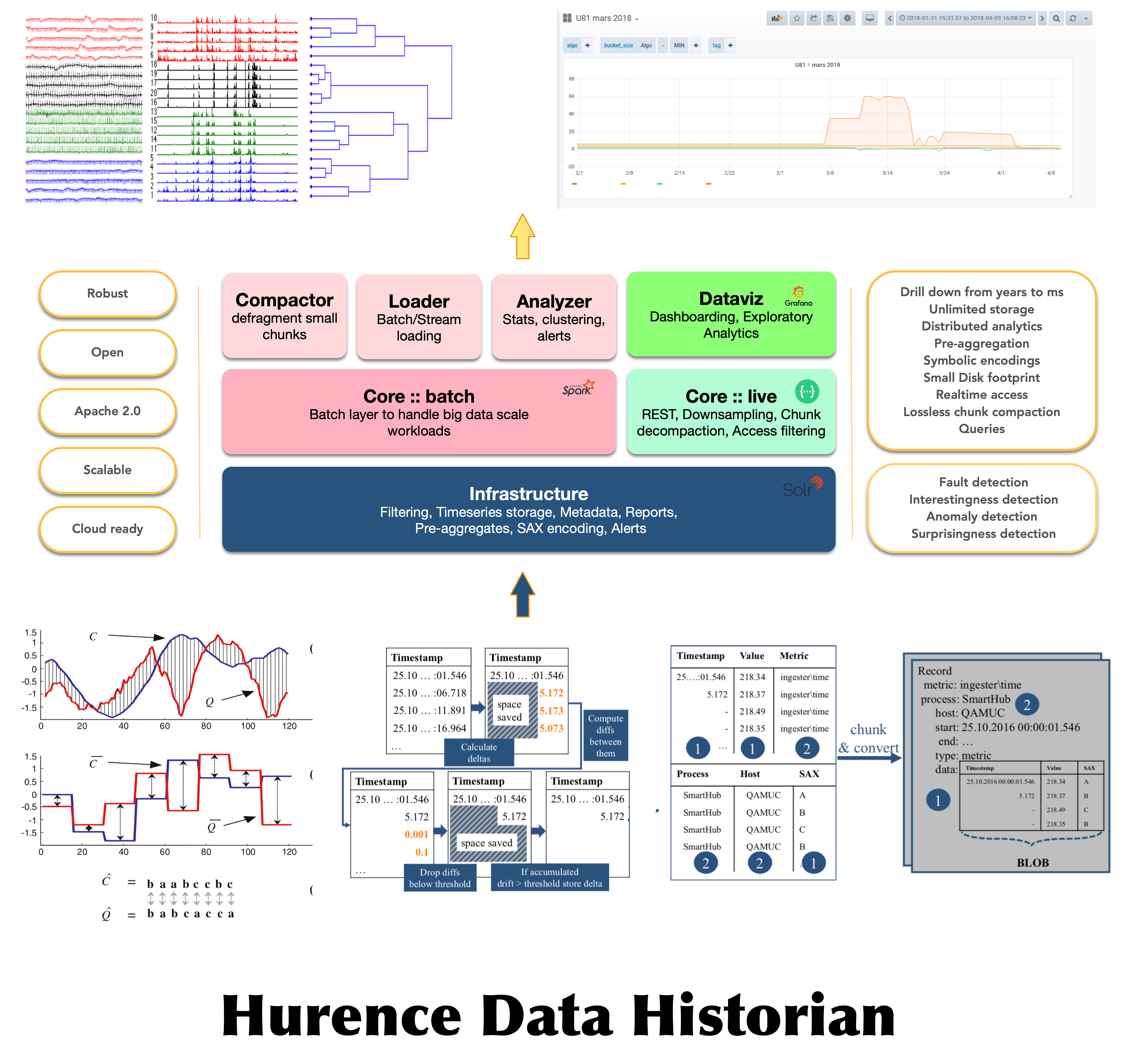
Architecture
Smart historian is stacked over somme key layers :
- historian-timeseries : A chunk & measure core library. Written in Java and Protocol Buffers
- A distributed search engine backend as foundation stone. This will hold the chunks of data and ensure availability and scalability.
- historian-server : A REST API that forwards api calls to search backend and transduce chunks binary encoded bits into floating points values and vice versa.
- historian-spark : A Spark big data API to manipulate chunks and measures through a parallelized framework and bundled tools :
- spark loader to handle massive imports
- spark compactor to de-fragment small chunks in the system
- A machine learning toolkit to get insights from massive loads of chunks.
Overall view